bw西汉姆联两篇论文被软件工程领域CCF A类国际会议
FSE 2026录用
近日,bw西汉姆联智能运维实验室的两篇研究论文成功被软件工程领域的CCF A类国际顶级会议——ACM International Conference on the Foundations of Software Engineering (FSE) 2026 录用。该会议将于2026年7月5日至9日在加拿大蒙特利尔举办。以下是两篇论文的简介:
论文1:Aloha: Localizing Batch Failures in Large-scale Cloud Systems via Contrast Analysis and Human-in-the-Loop Agent
作者:张圣林,吴雨珈,任竞寰,孙永谦*,辜文蔚,张朝运,李立群,林庆维,Dongmei Zhang,Saravan Rajmohan,Chetan Bansal,马明华
作者单位:bw西汉姆联、微软
摘要
大规模云系统构成了现代计算的基础设施,由大量异构组件协同运行,为全球用户提供关键服务。单个故障(如服务中断或配置错误)即可同时影响成千上万的用户。这类大规模故障通常被称为批量故障,其特征是在短时间窗口内,同一主体下大量实例同时受到影响,且通常源于共享的根因。
高效处理此类故障依赖于异常定位,然而现有方法对工程师的支持仍然有限,使得该过程耗时且认知负担较重。为此,我们提出 Aloha,一种基于对比分析的人机协同智能体框架,用于异常定位。
Aloha 将批量故障处理的完整流程进行系统化落地,为工程师提供面向场景理解、数据准备与诊断决策的引导,并输出可解释的根因模式。在微软云平台真实批量故障案例上的试点结果表明,Aloha 能够简化数据处理流程,支持基于对比的异常定位,并显著提升批量故障定位方法的可用性与实践性,为构建以人为中心、具备可扩展性的故障管理体系迈出了重要一步。
背景与挑战
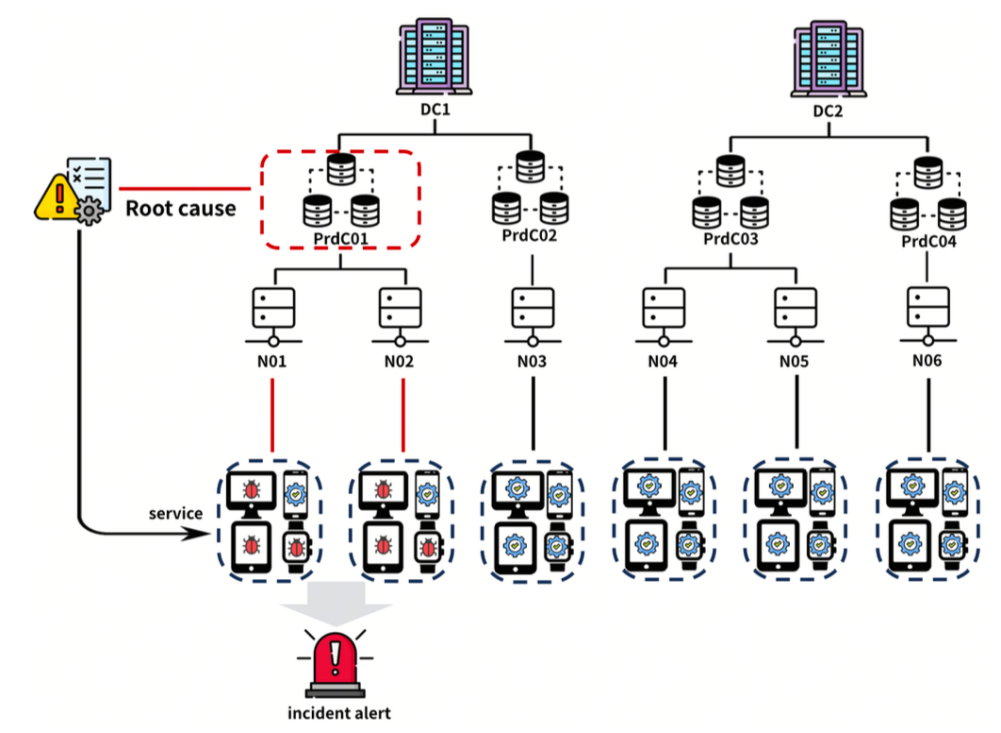
图 1:云系统中批量故障的示例。两个数据中心承载多个集群(如PrdC01–PrdC04),每个集群包含若干节点,为终端用户提供服务。当 某个集群(如PrdC01)发生故障时,异常会传播至其下属节点(Node01–Node02),从而引发大规模服务中断,并触发聚合告警。这一过程典型地展示了批量故障在云环境中的形成方式。
大规模云系统承载关键服务,单个故障(如配置错误或基础设施异常)即可在短时间内影响大量实例,形成批量故障。此类故障通常源于共享根因,其高效处理依赖于从大量异常实例中快速定位关键组件或配置。
尽管基于对比分析的方法在异常定位中展现出潜力,但在实际运维中仍面临三方面挑战:
1.场景理解困难: 原始数据来源多样且语义异构,工程师需判断是否构成批量故障并完成数据映射,认知成本高。
2.数据质量不可靠: 表格化过程中常存在标签不清、属性不合理或缺失值等问题,而现有方法缺乏对数据准备的指导。
3.诊断策略难以适配: 异常定位依赖目标函数与参数配置,但现有工作对策略选择支持有限,需人工反复调优。
核心方法与系统架构
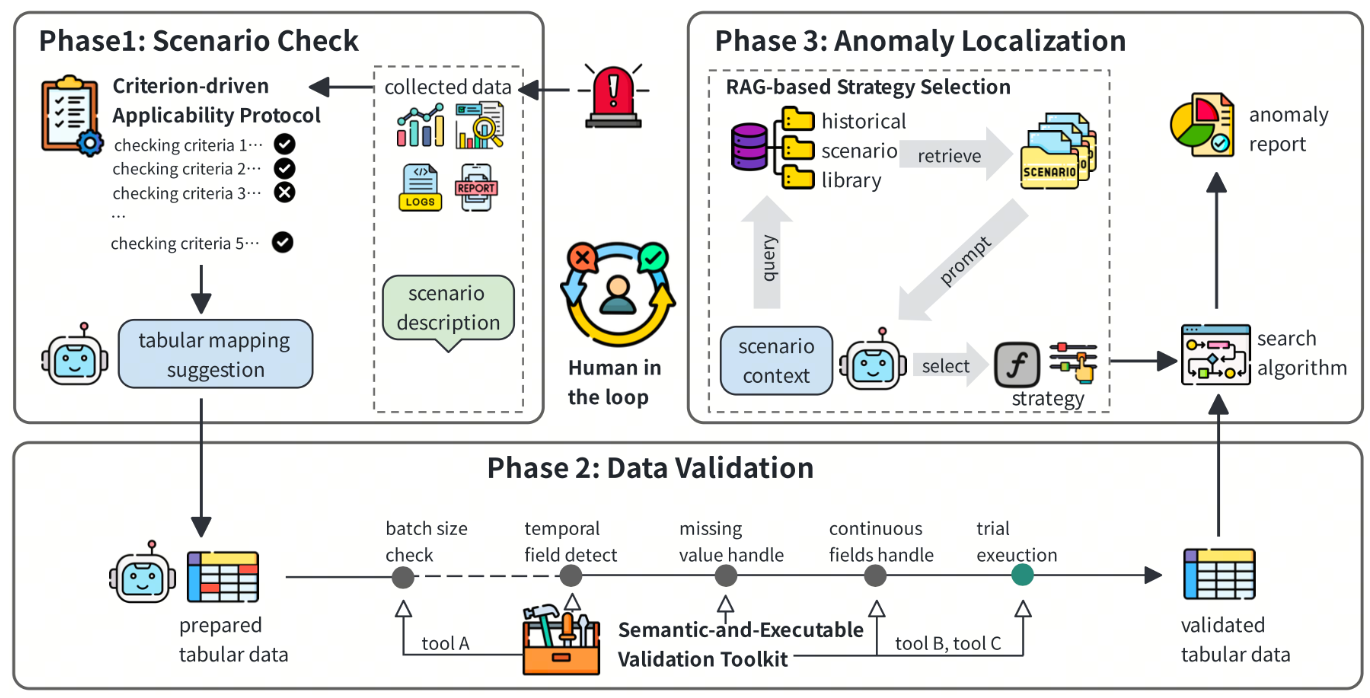
图 2:Aloha 在面对输入告警时的整体工作流程。
Aloha 框架采用三阶段架构:
•场景确认阶段:判断当前故障是否属于批量故障,并分析其是否满足对比分析的适用条件,同时指导原始数据向结构化表示的映射过程。
•数据校验阶段:对结构化数据进行一致性与语义完整性检查,识别潜在的数据问题并确保其满足异常定位的输入要求。
•异常定位阶段:基于对比分析执行模式搜索,定位潜在根因,并生成可解释的诊断结果。
整个流程均采用人机协同机制,在关键决策点引导工程师参与,以降低认知负担并提升诊断可靠性。
Aloha 框架的主要模块包括:
1.适用性判定协议:用于系统化判断批量故障场景及方法适用性。
2.语义与可执行校验工具:用于数据结构化验证与可执行性检查。
3.基于检索增强的策略选择:用于推荐异常定位的目标函数与搜索策略。
实验验证与部署成效
表 1:根因定位准确率对比
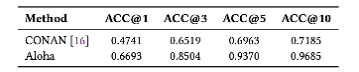
我们在微软云服务系统中部署了 Aloha 的概念验证版本,并在真实批量故障案例上进行了验证。与人工诊断流程及现有方法 CONAN 对比,结果表明 Aloha 在异常定位中具有较高准确性,在 93.7% 的案例中能够在 Top 5 推荐结果中覆盖真实根因。
此外,工程师反馈显示 Aloha 将单个故障案例的处理时间由约 10 小时显著降低至约半小时,大幅提升了诊断效率并降低了运维负担。
研究意义与展望
本研究初步表明,Aloha 通过引入人机协同与基于对比分析的异常定位框架,有助于提升批量故障诊断的效率,并为工程师提供更结构化的分析过程。实践反馈显示,该框架能够在一定程度上降低诊断过程中的认知负担。
未来,我们将进一步扩大验证范围并开展更系统的定量评估,同时持续改进系统的鲁棒性与人机协同机制,以提升其在复杂实际场景中的稳定性与适用性。
论文2:Bridging the Delay: Lag-Aware Spatio-Temporal Causal Inference for Microservice Root Cause Analysis
作者:张圣林,匡俊骅,张一萌,夏思博,冯金涛,王静宇,辜文蔚,孙永谦*,李伟,张瓅玶,裴丹
作者单位:bw西汉姆联、阿里巴巴、清华大学
摘要
微服务架构已成为现代互联网与云服务系统的核心支撑。然而,随着服务数量不断增长、依赖关系日益复杂,局部故障极易沿调用链逐步扩散,演化为大范围级联异常。高效开展根因定位是保障系统稳定运行和用户体验的关键。论文指出,在实际微服务系统中,上游故障往往不会立刻导致下游出现告警,而是会经过若干秒甚至数分钟后,才在依赖服务中逐步显现。这种具有异步性和多时滞特征的传播过程,给现有根因定位方法带来了很大挑战。
为此,论文提出了一种面向微服务根因定位的时滞感知时空因果推断框架 LagRCA。该方法能够显式建模故障在服务之间以不同时滞传播的过程,同时区分“真实因果影响”与“仅由指标同步波动带来的伪相关”,从而更准确地还原故障传播链条并定位真正根因。实验结果表明,LagRCA 在公开基准与真实工业数据集上均优于现有先进方法,并已部署于阿里巴巴生产环境,提升了故障诊断效率,减少了人工排障开销。
背景与挑战
在微服务系统中,一个上游服务的轻微性能抖动,往往会经过重试机制、消息队列缓冲、超时策略等运行机制逐步影响下游服务,不同服务出现异常的时间并不一致,而是具有明显的多时滞传播特征。论文通过案例分析指出,传统根因定位方法通常默认服务间影响是同步发生的,难以正确对齐“上游原因”与“下游症状”,从而容易削弱真正上游根因的重要性,反而将被动受影响的下游服务错误排在前列。
与此同时,微服务根因定位通常依赖两类图结构信息:一类是由调用链恢复得到的物理拓扑图,描述服务之间“谁调用谁”;另一类是由指标波动关系构建的性能相关图,描述服务之间“谁和谁变化相似”。前者结构清晰但可能遗漏隐藏依赖,后者信息丰富但容易受共同原因和噪声干扰。若直接将二者混合使用,模型很容易把“同步波动”误判为“直接因果”,从而引入虚假依赖边,误导根因定位。
因此,论文重点面向以下两项挑战展开研究:
1.如何建模动态变化的异步传播时滞:故障从上游传播至不同下游服务,通常具有异构且随场景变化的时滞,若仍采用同步或固定滞后建模,便难以正确关联原因与症状。
2.如何弥合物理拓扑与性能相关之间的差距:调用拓扑与指标共波动之间常存在不一致,仅依赖其中任意一种都不足以准确恢复真实传播路径。
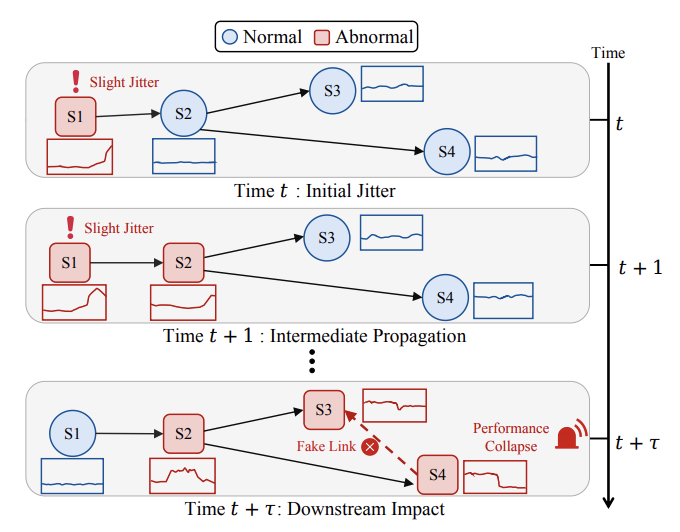
图 1:微服务系统中的滞后故障传播示意图。各服务实例旁展示了对应的 KPI 时序变化。
核心方法与系统架构
针对上述问题,论文提出了 LagRCA 框架,将微服务根因定位建模为一个时滞感知的时空因果推断问题。整体上,LagRCA 由数据预处理和三个核心模块组成,形成离线训练与在线诊断相结合的工作流程。
首先,在数据预处理阶段,方法将原始多模态可观测数据转换为统一的实例级健康状态序列,为后续建模提供标准化输入。论文主要利用指标与调用链两类数据:调用链用于恢复动态服务拓扑,指标序列用于刻画各服务实例随时间变化的运行状态。
随后,在动态多时滞因果图学习模块中,LagRCA 构建一组带有不同时间滞后的因果图,用于描述“某一时刻的上游实例如何影响若干时刻之后的下游实例”。该模块进一步将因果关系分解为“离散结构”和“连续强度”两部分,从而分别表示边是否存在以及影响强弱。这样的设计能够在保留物理拓扑可解释性的同时,更灵活地适应运行时不断变化的服务交互模式,并降低性能相关带来的伪因果干扰。
在时滞感知时空表示学习模块中,方法利用所学习到的多时滞因果图作为结构先验,设计了时滞感知的时空注意力机制,将不同时间滞后的上游上下文信号与当前服务状态进行对齐与融合,使模型能够显式捕获“上游异常如何在延迟后演化为下游偏离”的传播规律。
最后,在上游调整根因推断模块中,LagRCA 不再直接依据异常分数对服务排序,而是显式扣除那些“可由上游传播解释”的异常部分,从而降低下游受害者因异常放大而被误判为根因的风险。与此同时,方法还能输出可解释的故障传播路径,帮助工程师理解故障是如何沿服务链逐步扩散的。
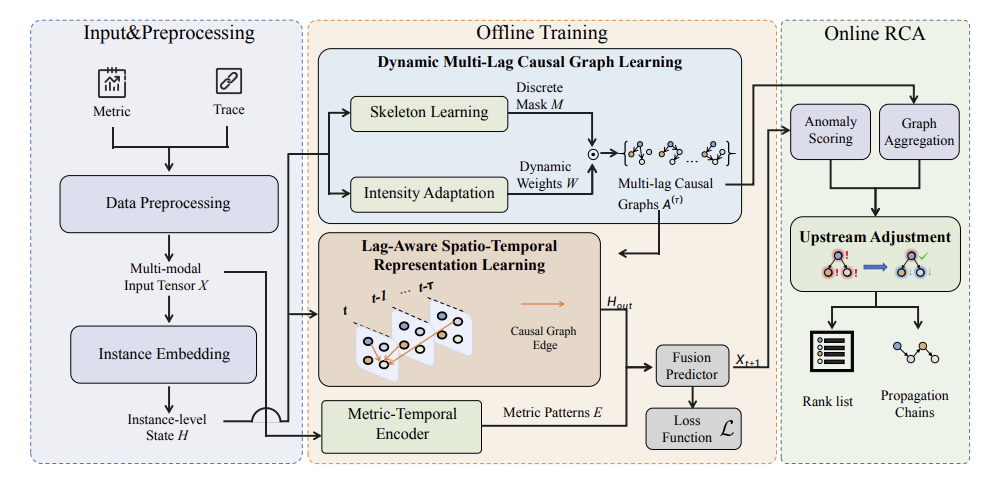
图 2:LagRCA 框架图
实验验证
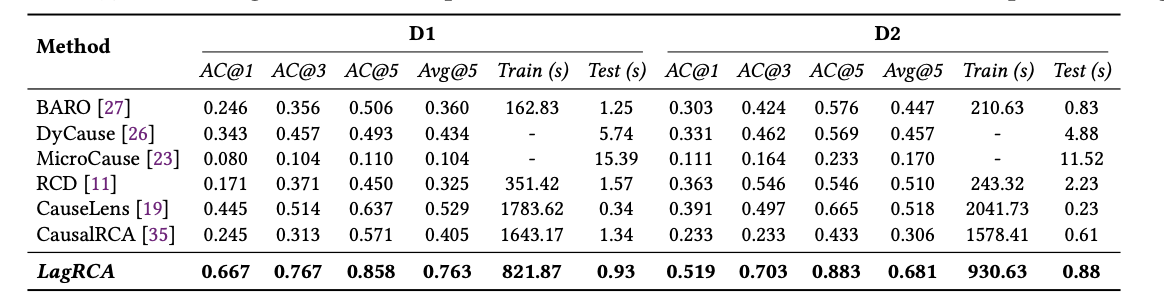
论文在两个具有代表性的数据集上对 LagRCA 进行了系统评估:其一是来源于真实生产环境的工业级微服务数据集 D1,包含 46 个微服务实例与 146 个故障案例;其二是基于 Online Boutique 构建的公开基准数据集 D2,包含 41 个微服务实例与 161 个故障案例。实验结果表明,LagRCA 在两个数据集上的根因定位准确率均显著优于 BARO、DyCause、CauseLens、RCD、MicroCause、CausalRCA 等代表性方法。
在工业数据集 D1 上,LagRCA 的 AC@1 达到 0.667,AC@5 达到 0.858,Avg@5 达到 0.763;在公开数据集 D2 上,分别达到 0.519、0.883 和 0.681,整体表现均优于对比方法。论文分析认为,这一优势主要来自对多时滞传播的显式建模,以及对上游传播影响的有效扣除,使模型能够更稳定地优先识别真正的故障源头,而非只是异常表现更明显的下游服务。
表 1:不同方法的根因定位性能
研究意义与展望
本研究面向微服务系统中长期存在的“故障传播有延迟、因果关系易混淆”这一核心难题,提出了一个兼顾时空传播规律、因果结构学习与工业可部署性的根因定位框架。相较于将服务交互简单视为同步关系的传统方法,LagRCA 更贴合真实生产环境中故障逐步扩散、影响层层传递的实际特点,为复杂系统中的高精度根因定位提供了新的思路。
未来,相关研究可进一步拓展到更复杂的多模态诊断场景,例如纳入日志等更多观测信息,持续提升因果结构学习的鲁棒性与传播解释能力,并推动该框架在更大规模、更复杂业务场景中的应用落地。


 津南校区地址:天津市津南区海河教育园同砚路38号
津南校区地址:天津市津南区海河教育园同砚路38号
 邮编:300350
邮编:300350